深度学习是机器学习中的一个重要的方向,深度学习其实就是神经网络学习,这里“深度”就是说神经网络中众多的层。
那么深度学习是用来干嘛的呢?简单说,那就是...
分类关于什么是机器学习的解释,Quora上有一个买菜大妈都能看的懂的回答。翻译一下就是,吃遍南山区所有芒果的大妈,自己总结出个大颜色黄的比较好吃,所以买芒果的时候,直接挑选了这种。那什么是机器学习呢,就是你告诉机器每一个芒果的特征(颜色,大小,软硬等),并且告诉机器其输出(好不好吃),剩下的就等机器去学习出一套规则,这些芒果就是你的训练集。而当你再丢芒果进去的时候,已然熟悉基本法的机器就会直接告诉你这个芒果好不好吃,这种能自动对输入的东西进行分类的机器,就叫做分类器。

分类器的目标就是让正确分类的比例尽可能高。一般我们需要首先收集一些样本,人为标记上正确分类结果,然后用这些标记好的数据训练分类器,训练好的分类器就可以在新来的特征向量上工作了。
神经元我们再来看看神经网络是怎么工作的。

最简单地把这两组特征向量分开的方法是什么呢?当然是在两组数据中间画一条竖直线,直线左边是-,右边是+,分类器就完成了。以后来了新的向量只要代入公式,h = ax + b ,凡是落在直线左边的都是-,落在右边的都是+。这是二维空间的分类,而当特征有很多种时,我们就要在n维空间做分类,大家可以想象一下,就是用一个n-1维超平面把n维空间一分为二,两边分属不同的两类,,这种分类器就叫做神经元,a是权值,a0是偏移。

这么一画是不是就很像人脑的神经元呀,我们就用这些神经元组成网络去学习训练集的数据,求出最优的权值(weights)和偏置(biases)以便最终正确地分类。
神经网络
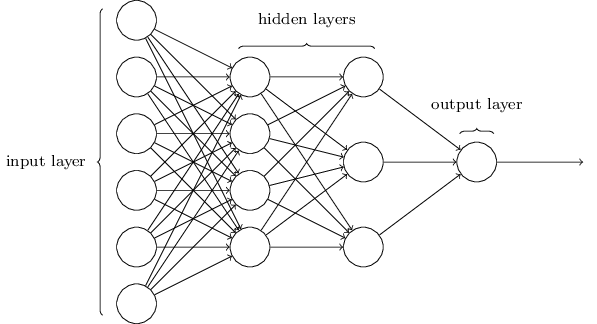
上图就是一个简单神经网络的架构,网络中最左边的一层被称作输入层,其中的神经元被称为输入神经元(input neurons)。最右边的一层是输出层(output layer),包含的神经元被称为输出神经元(output neurons)。网络中间的一层被称作隐层(hidden layer),在一些网络中往往有多个隐层。我们可以看到,输入向量连到许多神经元上,这些神经元的输出又连到一堆神经元上,这一过程可以重复很多次。数值向量在不同神经元之间传导。
但是,我们刚刚分析了神经元,神经元的变换是完全的线形的,如果神经网络的每层都只是做线性变换,多层输入叠加后也还是线性变换。因为线性模型的表达能力不够,所以需要激活函数来引入非线性因素。举个栗子,常用的激活函数sigmoid 函数,可以将实数压缩到[0,1]之间。激活函数是神经网络强大的基础,好的激活函数(根据任务来选择)还可以加速训练。
函数,可以将实数压缩到[0,1]之间。激活函数是神经网络强大的基础,好的激活函数(根据任务来选择)还可以加速训练。
接下来,确定了神经网络的连接方式、网络的层数、每层的节点数,建好网络模型之后,我们要开始学习这个神经网络的每个连接上的权值了。
训练网络(training)训练过程就是用训练数据的input经过网络计算出output,再和label计算出loss,再计算出gradients来更新weights的过程。label就是训练集里预先加上的分类标记,loss就是你算出的结果与正确结果(正确为1,错误为0)的误差,或者叫损失。
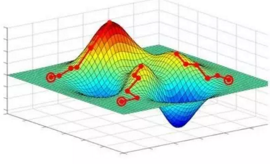
那么training其实就是通过梯度下降法尽可能缩小loss的过程。如下图所示,我们希望loss值可以降低到右侧深蓝色的最低点。
具体步骤如下:
正向传递:算当前网络的预测值 (Relu是一种激活函数,Wh1、Wh2、W0是权重,b是偏移量)
计算loss:
计算梯度:从loss开始反向传播计算每个参数(parameters)对应的梯度(gradients)。这里用Stochastic Gradient Descent (SGD) 来计算梯度,即每次更新所计算的梯度都是从一个样本计算出来的。
更新权重:这里用最简单的方法来更新,即所有参数都

预测新值:训练过所有样本后,打乱样本顺序再次训练若干次。训练完毕后,当再来新的数据input,就可以利用训练的网络来预测了。这时的output就是效果很好的预测值了。
PS 以上理论知识和公式来自斯坦福大学计算机视觉实验室推出的课程CS231n: Convolutional Neural Networks for Visual Recognition
调戏Tensorflow Playground接下来,摩拳擦掌想要试一试深度学习的朋友们可以试着调戏一下TensorFlow Playground。TensorFlow游乐场是一个通过网页浏览器就可以训练的简单神经网络,并实现了可视化训练过程的工具。下图就是TensorFlow游乐场默认设置的截图。
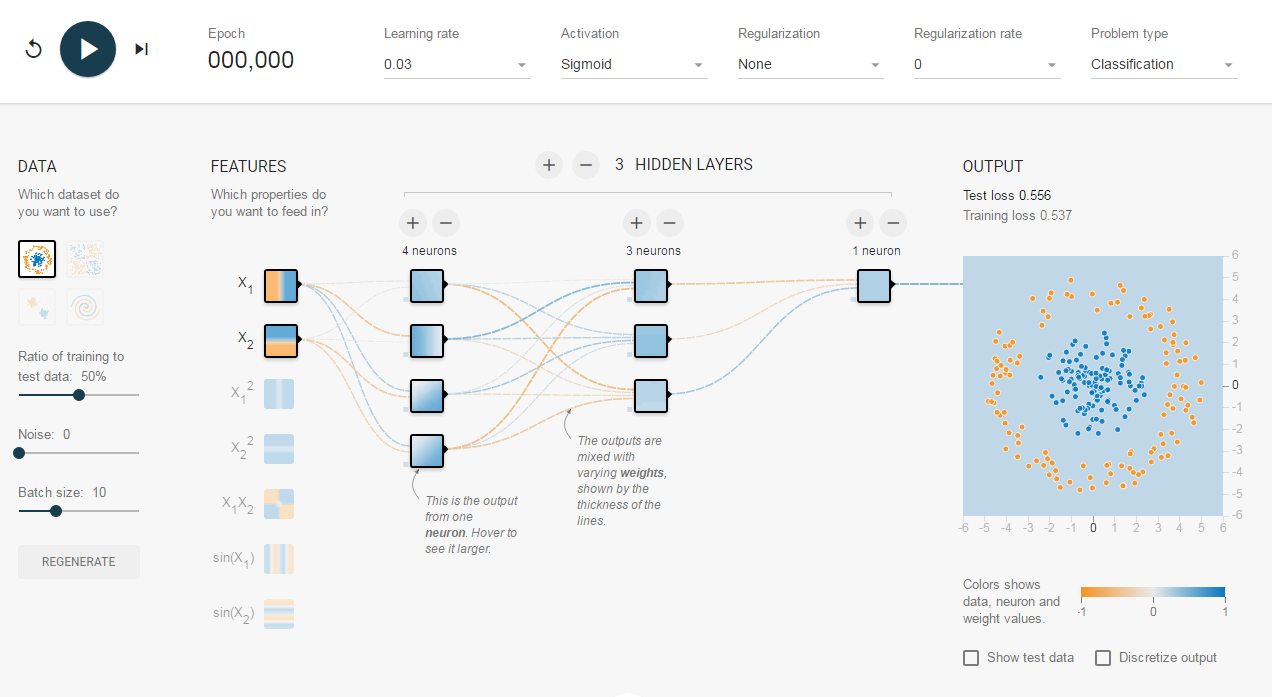
左边的每组数据,都是不同形态分布的一群点。每一个点,都与生俱来了2个特征:x1和x2,表示点的位置。数据中的点有2类:橙色和蓝色。我们这个神经网络的目标,就是通过训练,知道哪些位置的点是橙色、哪些位置的点是蓝色。如何确定网络结构呢?到底用不用隐层呢?还是一个隐层?两个隐层或更多?每个层的尺寸该多大?这些都可以在TP上调整,而且立刻就能看到直观的结果。快去试试吧~
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

